CSVs are ubiquitous. You'll find them everywhere.
If you're using Jupyter notebook setup, here is the code I used to initialize things:
# for jupyter notebook
from IPython.core.interactiveshell import InteractiveShell
InteractiveShell.ast_node_interactivity='all'
# import relavant python modules
from pyspark.sql import types as T
from pyspark.sql import functions as F
# Create spark session (not required on databricks)
from pyspark.sql import SparkSession
spark = SparkSession.builder.master("local[*]").getOrCreate()
Read CSV
The barebones read method template is:
sales_df = (
spark
.read
.format("csv") # set data type format
.load("/data/sales/") # set load location
)
i
Note: Instead of using format().load() to set the data format type and data location, you can directly use the format-specific csv() to set both data format and location through a single method.
sales_df = (
spark
.read
.csv("/data/sales/")
)
However, it is recommended that you stick to using the standard template of .format().load(). It keeps your codebase more uniform.
In this article, I'm sticking to the .format().load() way of loading csv.
A more practical read command will:
- Set column names from the csv files' header
- Automatically infer schema from loaded data (schema on read)
sales_df = (
spark
.read
.format("csv")
.option("header", "true")
.option("inferschema", "true") # optional option
.load("/data/sales/")
)
Set schema
Infer schema is not always accurate. Sometimes, you simply know your data better than the spark engine. In this case, set the dataframe's schema manually.
Keep in mind that you're defining the schema of the dataframe (the data that has been loaded into the dataframe). You aren't defining the schema of the source file.
Automatically set schema using inferSchema
sales_df = (
spark
.read
.format("csv")
.option("header", "true")
.option("inferschema", "true") # optional option
.load("/data/sales/")
)
Manually set schema
There are 2 ways to set schema manually:
- Using DDL string
- Programmatically, using
StructTypeandStructField
Set schema using DDL string
This is the recommended way to define schema, as it is the easier and more readable option. These datatypes we use in the string are the Spark SQL datatypes.
The format is simple. It is a string-csv of the dataframe's every column name & datatype.
schema_ddl_string = "<column_name> <data type>, <column_name> <data type>, <column_name> <data type>"
sales_schema_ddl = """year INT, month INT, day INT, amount DECIMAL"""
sales_df = (
spark
.read
.format("csv")
.schema(sales_schema_ddl) # set schema
.option("header", "true")
.load("/data/sales/")
)
The datatypes you can use for DDL string are:
| Data type | SQL name |
|---|---|
| BooleanType | BOOLEAN |
| ByteType | BYTE, TINYINT |
| ShortType | SHORT, SMALLINT |
| IntegerType | INT, INTEGER |
| LongType | LONG, BIGINT |
| FloatType | FLOAT, REAL |
| DoubleType | DOUBLE |
| DateType | DATE |
| TimestampType | TIMESTAMP, TIMESTAMP_LTZ |
| TimestampNTZType | TIMESTAMP_NTZ |
| StringType | STRING |
| BinaryType | BINARY |
| DecimalType | DECIMAL, DEC, NUMERIC |
| YearMonthIntervalType | INTERVAL YEAR, INTERVAL YEAR TO MONTH, INTERVAL MONTH |
| DayTimeIntervalType | INTERVAL DAY, INTERVAL DAY TO HOUR, INTERVAL DAY TO MINUTE, INTERVAL DAY TO SECOND, INTERVAL HOUR, INTERVAL HOUR TO MINUTE, INTERVAL HOUR TO SECOND, INTERVAL MINUTE, INTERVAL MINUTE TO SECOND, INTERVAL SECOND |
| ArrayType | ARRAY |
| StructType | STRUCT Note: ‘:’ is optional. |
| MapType | MAP |
Source - Spark SQL - Supported Data Types
Set schema using python API functions
We define a column's datatype using the StructField() method.
To define the schema of the entire dataframe, we -
- Create a
StructField("column_name", DataType())that defines datatype of one column of the dataframe - Create a list of
StructField(), to define the data type of every column in the dataframe - Pass list of
StructFields into aStructType() - Pass the
StructType()object to theschema()method ofDataFrameReader.read
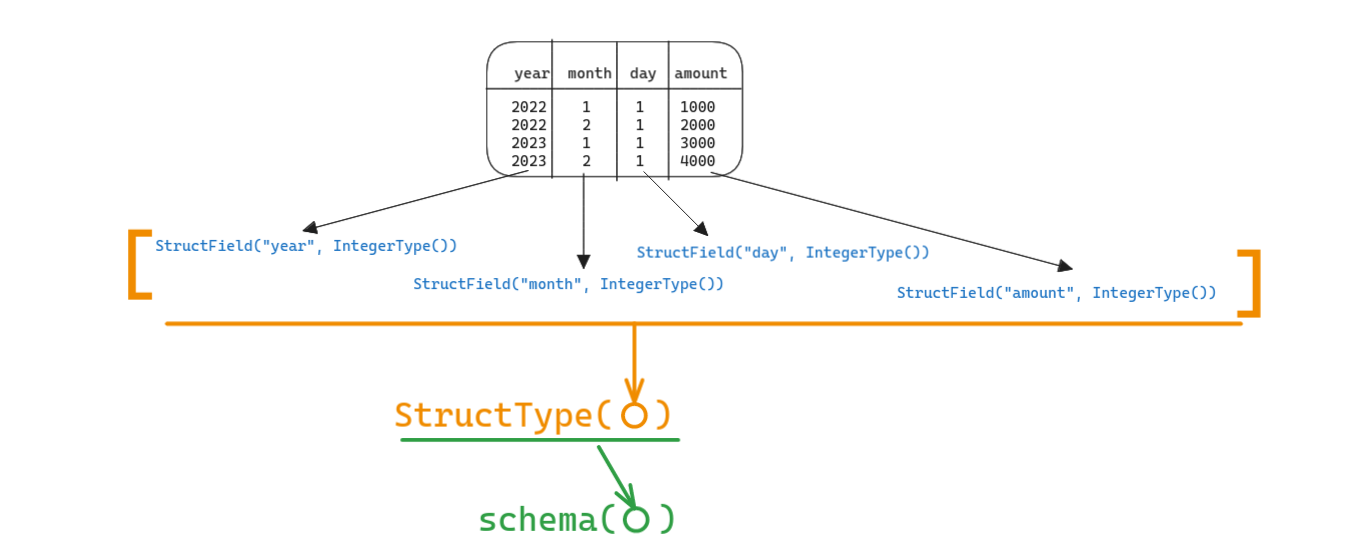
It looks easier if you directly look at the code:
from pyspark.sql import types as T
sales_schema_struct = T.StructType(
[
T.StructField("year", T.IntegerType()),
T.StructField("month", T.IntegerType()),
T.StructField("day", T.IntegerType()),
T.StructField("amount", T.DecimalType()),
]
)
sales_df = (
spark
.read.format("csv")
.schema(sales_schema_struct) # set schema
.option("header", "true")
.load("/data/sales/")
)
The datatypes you can use in StructField() are:
| Data type | Value type in Python | API to access or create a data type |
|---|---|---|
| ByteType | int or long Note: Numbers will be converted to 1-byte signed integer numbers at runtime. Please make sure that numbers are within the range of -128 to 127. |
ByteType() |
| ShortType | int or long Note: Numbers will be converted to 2-byte signed integer numbers at runtime. Please make sure that numbers are within the range of -32768 to 32767. |
ShortType() |
| IntegerType | int or long | IntegerType() |
| LongType | long Note: Numbers will be converted to 8-byte signed integer numbers at runtime. Please make sure that numbers are within the range of -9223372036854775808 to 9223372036854775807. Otherwise, please convert data to decimal.Decimal and use DecimalType. |
LongType() |
| FloatType | float Note: Numbers will be converted to 4-byte single-precision floating point numbers at runtime. |
FloatType() |
| DoubleType | float | DoubleType() |
| DecimalType | decimal.Decimal | DecimalType() |
| StringType | string | StringType() |
| BinaryType | bytearray | BinaryType() |
| BooleanType | bool | BooleanType() |
| TimestampType | datetime.datetime | TimestampType() |
| TimestampNTZType | datetime.datetime | TimestampNTZType() |
| DateType | datetime.date | DateType() |
| DayTimeIntervalType | datetime.timedelta | DayTimeIntervalType() |
| ArrayType | list, tuple, or array | ArrayType(elementType, [containsNull]) Note:The default value of containsNull is True. |
| MapType | dict | MapType(keyType, valueType, [valueContainsNull]) Note:The default value of valueContainsNull is True. |
| StructType | list or tuple | StructType(fields) Note: fields is a Seq of StructFields. Also, two fields with the same name are not allowed. |
| StructField | The value type in Python of the data type of this field (For example, Int for a StructField with the data type IntegerType) |
StructField(name, dataType, [nullable]) Note: The default value of nullable is True. |
Source - Spark SQL - Supported Data Types
Write CSV
The barebones write method template is:
sales_df.write.format("csv").save("/data/sales")
A more practical write command will:
- Save column names into the file's header
- Explicitly set write mode
(
sales_df
.write
.format("csv")
.option("header", "true")
.mode("overwrite")
.save("/data/sales")
)
Partition written data on specific columns
To make reading data faster and more optimized, by increasing parallelization.
Eg - Partition by year, month, date:
(
sales_df
.write
.format("csv")
.option("header", "true")
.mode("overwrite")
.partitionBy("year", "date", "day")
.save("/data/sales")
)
Bucket written data on specific columns
To break down the file sizes within each partition.
Note :
save()doesn't support saving after usingbucketBy(). OnlysaveAsTable()suports it.If you use
save(), it will throw an exceptionAnalysisException: 'save' does not support bucketBy right now.
Eg - Create 10 buckets within each partition:
(
sales_df
.write
.format("csv")
.mode("overwrite")
.option("header", "true")
.option("path", "data/sales")
.bucketBy(10, "year", "date", "day")
.saveAsTable("sales")
)
More details in bucketBy() documentation
List of options
Source - CSV data source options documentation
| Property Name | Default | Meaning | Scope |
|---|---|---|---|
sep |
, | Sets a separator for each field and value. This separator can be one or more characters. | read/write |
encoding |
UTF-8 | For reading, decodes the CSV files by the given encoding type. For writing, specifies encoding (charset) of saved CSV files. CSV built-in functions ignore this option. | read/write |
quote |
" | Sets a single character used for escaping quoted values where the separator can be part of the value. For reading, if you would like to turn off quotations, you need to set not null but an empty string. For writing, if an empty string is set, it uses u0000 (null character). |
read/write |
quoteAll |
false | A flag indicating whether all values should always be enclosed in quotes. Default is to only escape values containing a quote character. | write |
escape |
|Sets a single character used for escaping quotes inside an already quoted value. | read/write | |
escapeQuotes |
true | A flag indicating whether values containing quotes should always be enclosed in quotes. Default is to escape all values containing a quote character. | write |
comment |
Sets a single character used for skipping lines beginning with this character. By default, it is disabled. | read | |
header |
false | For reading, uses the first line as names of columns. For writing, writes the names of columns as the first line. Note that if the given path is a RDD of Strings, this header option will remove all lines same with the header if exists. CSV built-in functions ignore this option. | read/write |
inferSchema |
false | Infers the input schema automatically from data. It requires one extra pass over the data. CSV built-in functions ignore this option. | read |
preferDate |
true | During schema inference (inferSchema), attempts to infer string columns that contain dates as Date if the values satisfy the dateFormat option or default date format. For columns that contain a mixture of dates and timestamps, try inferring them as TimestampType if timestamp format not specified, otherwise infer them as StringType. |
read |
enforceSchema |
true | If it is set to true, the specified or inferred schema will be forcibly applied to datasource files, and headers in CSV files will be ignored. If the option is set to false, the schema will be validated against all headers in CSV files in the case when the header option is set to true. Field names in the schema and column names in CSV headers are checked by their positions taking into account spark.sql.caseSensitive. Though the default value is true, it is recommended to disable the enforceSchema option to avoid incorrect results. CSV built-in functions ignore this option. |
read |
ignoreLeadingWhiteSpace |
false (for reading), true (for writing) |
A flag indicating whether or not leading whitespaces from values being read/written should be skipped. | read/write |
ignoreTrailingWhiteSpace |
false (for reading), true (for writing) |
A flag indicating whether or not trailing whitespaces from values being read/written should be skipped. | read/write |
nullValue |
Sets the string representation of a null value. Since 2.0.1, this nullValue param applies to all supported types including the string type. |
read/write | |
nanValue |
NaN | Sets the string representation of a non-number value. | read |
positiveInf |
Inf | Sets the string representation of a positive infinity value. | read |
negativeInf |
-Inf | Sets the string representation of a negative infinity value. | read |
dateFormat |
yyyy-MM-dd | Sets the string that indicates a date format. Custom date formats follow the formats at Datetime Patterns. This applies to date type. | read/write |
timestampFormat |
yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX] | Sets the string that indicates a timestamp format. Custom date formats follow the formats at Datetime Patterns. This applies to timestamp type. | read/write |
timestampNTZFormat |
yyyy-MM-dd'T'HH:mm:ss[.SSS] | Sets the string that indicates a timestamp without timezone format. Custom date formats follow the formats at Datetime Patterns. This applies to timestamp without timezone type, note that zone-offset and time-zone components are not supported when writing or reading this data type. | read/write |
enableDateTimeParsingFallback |
Enabled if the time parser policy has legacy settings or if no custom date or timestamp pattern was provided. | Allows falling back to the backward compatible (Spark 1.x and 2.0) behavior of parsing dates and timestamps if values do not match the set patterns. | read |
maxColumns |
20480 | Defines a hard limit of how many columns a record can have. | read |
maxCharsPerColumn |
-1 | Defines the maximum number of characters allowed for any given value being read. By default, it is -1 meaning unlimited length | read |
mode |
PERMISSIVE | Allows a mode for dealing with corrupt records during parsing. It supports the following case-insensitive modes. Note that Spark tries to parse only required columns in CSV under column pruning. Therefore, corrupt records can be different based on required set of fields. This behavior can be controlled by spark.sql.csv.parser.columnPruning.enabled (enabled by default). - PERMISSIVE: when it meets a corrupted record, puts the malformed string into a field configured by columnNameOfCorruptRecord, and sets malformed fields to null. To keep corrupt records, an user can set a string type field named columnNameOfCorruptRecord in an user-defined schema. If a schema does not have the field, it drops corrupt records during parsing. A record with less/more tokens than schema is not a corrupted record to CSV. When it meets a record having fewer tokens than the length of the schema, sets null to extra fields. When the record has more tokens than the length of the schema, it drops extra tokens.- DROPMALFORMED: ignores the whole corrupted records. This mode is unsupported in the CSV built-in functions.- FAILFAST: throws an exception when it meets corrupted records. |
read |
columnNameOfCorruptRecord |
(value of spark.sql.columnNameOfCorruptRecord configuration) |
Allows renaming the new field having malformed string created by PERMISSIVE mode. This overrides spark.sql.columnNameOfCorruptRecord. |
read |
multiLine |
false | Parse one record, which may span multiple lines, per file. CSV built-in functions ignore this option. | read |
charToEscapeQuoteEscaping |
escape or \0 |
Sets a single character used for escaping the escape for the quote character. The default value is escape character when escape and quote characters are different, \0 otherwise. |
read/write |
samplingRatio |
1.0 | Defines fraction of rows used for schema inferring. CSV built-in functions ignore this option. | read |
emptyValue |
(for reading), "" (for writing) |
Sets the string representation of an empty value. | read/write |
locale |
en-US | Sets a locale as language tag in IETF BCP 47 format. For instance, this is used while parsing dates and timestamps. | read |
lineSep |
\r, \r\n and \n (for reading), \n (for writing) |
Defines the line separator that should be used for parsing/writing. Maximum length is 1 character. CSV built-in functions ignore this option. | read/write |
unescapedQuoteHandling |
STOPATDELIMITER | Defines how the CsvParser will handle values with unescaped quotes. - STOP_AT_CLOSING_QUOTE: If unescaped quotes are found in the input, accumulate the quote character and proceed parsing the value as a quoted value, until a closing quote is found.- BACK_TO_DELIMITER: If unescaped quotes are found in the input, consider the value as an unquoted value. This will make the parser accumulate all characters of the current parsed value until the delimiter is found. If no delimiter is found in the value, the parser will continue accumulating characters from the input until a delimiter or line ending is found.- STOP_AT_DELIMITER: If unescaped quotes are found in the input, consider the value as an unquoted value. This will make the parser accumulate all characters until the delimiter or a line ending is found in the input.- SKIP_VALUE: If unescaped quotes are found in the input, the content parsed for the given value will be skipped and the value set in nullValue will be produced instead.- RAISE_ERROR: If unescaped quotes are found in the input, a TextParsingException will be thrown. |
read |
compression |
(none) | Compression codec to use when saving to file. This can be one of the known case-insensitive shorten names (none, bzip2, gzip, lz4, snappy and deflate). CSV built-in functions ignore this option. |
write |
Warning on column order in csv files
WARNING FOR CSV FILES
Spark assumes that the column order is same across all csv files. So, column order should not change across csv files.
Spark doesn't intelligently check column name in source file and then insert them in the proper column in the table. It will stupidly insert nth column in source file into nth column in table. It doesn't check if the column orders in the source file are different from column orders in the destination dataframe/table.
Example:
Consider 2 csv files with different column orders:
data1.csv
age,name
20,alice
25,bob
data2.csv
name,age
chad,30
dave,35
Now, when you load the two csv files, the data looks like this:
person_df = (
spark
.read
.format("csv") # set data type format
.option("header", "true")
.load(["/home/jovyan/data/data1.csv", "/home/jovyan/data/data2.csv"]) # set load location
)
person_df.show()
Output:
+----+-----+
| age| name|
+----+-----+
| 20|alice|
| 25| bob|
|chad| 30|
|dave| 35|
+----+-----+
You can see how age and name data got mixed up. So, always make sure the column order is same across all the csv files you are loading.